





































.
Enquanto o novo coronavírus continua se espalhando pelo mundo, assistimos à proliferação de uma série de gráficos mostrando a evolução da covid-19 e curvas ilustrando o que poderá acontecer no futuro. Além de assustador, o cenário traz uma série de desafios adicionais para os cientistas da computação: como extrair conhecimentos úteis a partir dessa quantidade gigantesca de informações que circulam na internet sobre a pandemia, aproveitando os recursos tecnológicos que temos à disposição?
Esse é um desafio que já vem sendo enfrentado pelos pesquisadores do Instituto de Ciências Matemáticas e de Computação (ICMC) da USP, em São Carlos. Eles têm obtido bons resultados utilizando técnicas de inteligência artificial aplicadas à mineração de dados nas áreas de agronegócio e educação, por exemplo. Para isso, desenvolvem desde 2014 uma ferramenta chamada Websensors, que usa inteligência artificial para analisar eventos extraídos de textos de notícias, tais como informações sobre o que aconteceu, como, quando, onde e quem está envolvido.
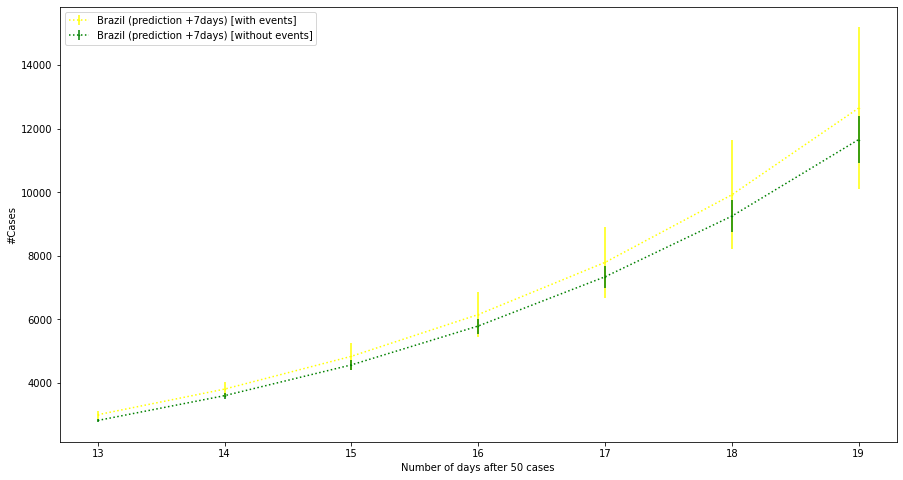
Agora, estão empenhados em coletar eventos mencionando o novo coronavírus ou a doença covid-19. A meta é usar essas informações como conhecimento complementar para ser incorporado em modelos de previsão já existentes. Um exemplo é a previsão da curva de contaminação da pandemia, que pode ser ajustada considerando eventos sobre esse assunto. Além disso, esse conhecimento adicional será importante para apoiar especialistas na identificação futura de iniciativas bem-sucedidas e mal-sucedidas no combate ao vírus, o que terá grande utilidade nas próximas epidemias que enfrentaremos.

“Quando olhamos para a evolução futura da curva de contaminação de uma doença e levamos em conta apenas dados sobre contágios que aconteceram no passado, temos uma visão limitada do problema. Se for possível enriquecer essa visão, adicionando à previsão informações extraídas de fontes confiáveis, acreditamos que poderemos incrementar nosso olhar e, quem sabe, construir modelos preditivos mais próximos da realidade”, explica Solange Rezende, que coordena o projeto junto com o professor Ricardo Marcacini, ambos do Laboratório de Inteligência Computacional do ICMC. A iniciativa conta, ainda, com a participação de dois doutorandos, quatro mestrandos e três pesquisadores colaboradores, como Rafael Geraldeli Rossi, ex-aluno do ICMC que é professor na Universidade Federal de Mato Grosso do Sul.
Web, um poderoso sensor
Vamos imaginar que você encontrasse um viajante do tempo hoje que lhe perguntasse: qual a maneira mais rápida e confiável de compreender o que está acontecendo no mundo em tempo real? É provável que sua resposta fosse: entre na internet. Sim, de fato, é pela web que temos acesso a fontes de informações confiáveis e seguras de todo o mundo, em várias línguas. É por isso que muitos pesquisadores começaram a usar as informações da web da mesma maneira que já utilizamos sensores para medir, por exemplo, a temperatura, a umidade, a quantidade de chuva, a velocidade e a direção dos ventos em um lugar. São os dados captados por esses sensores ao longo do tempo – a variação da temperatura, umidade, chuva e vento – que possibilitaram aos cientistas construírem os modelos para prever o clima no futuro.
Ora, pense que as informações que circulam na web também podem funcionar como esses sensores e ajudar não apenas um viajante do tempo a compreender nossa realidade, mas também permitir que os pesquisadores desenvolvam novos modelos de previsão de futuro. “Isso acontece porque os computadores conseguem processar uma grande quantidade de informações e encontrar padrões no que aconteceu no passado e que poderá se repetir no futuro”, explica Marcacini.
No caso da covid-19, os links da web são captados por meio de uma plataforma internacional chamada GDELT. A seguir, os pesquisadores do ICMC coletam as notícias que se referem especificamente à doença ou ao coronavírus, desde que sejam provenientes de fontes confiáveis, e fazem um pré-processamento. Nessa etapa, utilizando várias técnicas, como as de processamento de linguagem natural, os textos são transformados em um conjunto de sinais. É como se houvesse uma tradução da linguagem humana para uma linguagem que as máquinas conseguem compreender.
Na sequência, esses sinais são inseridos no circuito de uma rede neural. Tal como no cérebro humano, em que os sinais que captamos por meio dos nossos sentidos vão sendo processados, a rede neural analisa as características extraídas dos textos coletados e dá um peso diferente a cada uma, de acordo com a maior ou menor frequência em que a característica surge na coletânea. É comparável ao trabalho que nossos neurônios realizam depois que os olhos captam várias imagens diferentes e vamos identificar o que há em comum entre elas. Mas lembre-se de que, nesse caso, estamos falando de encontrar padrões em uma gigantesca quantidade de textos, um trabalho impossível de ser realizado manualmente e que pode resultar em valiosos conhecimentos, como já demonstrado em vários estudos.
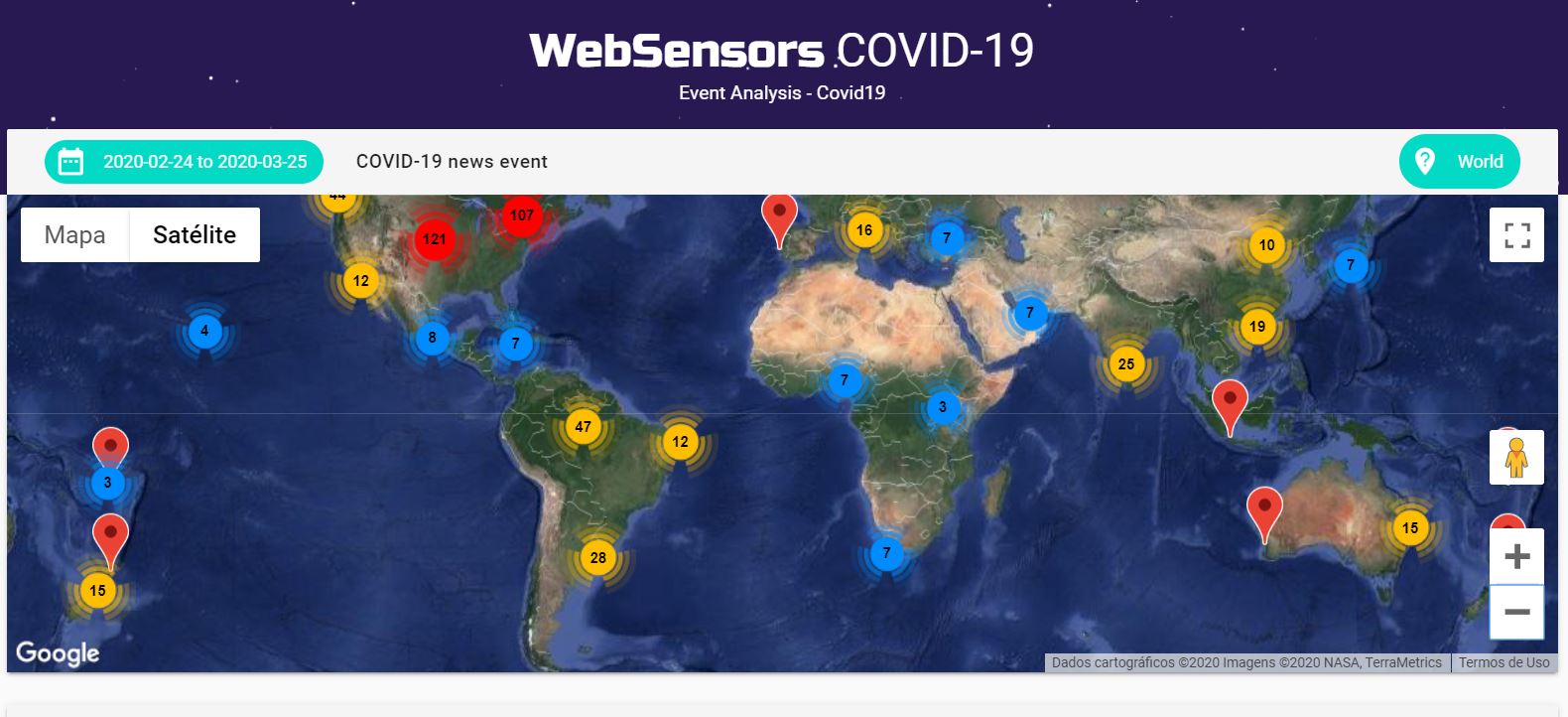
Em todo o globo, de 19 a 24 de março, a plataforma criada pelo grupo de pesquisadores do ICMC (http://websensors.net.br/
.
.
Aplicação na agricultura e no combate à evasão escolar



